
Notre workflow Git, pourquoi, comment
Depuis l’avènement d’outils de gestion de code source de bonne qualité (Git et mercurial principalement) et surtout qui ne vous brident — presque — plus, vous pouvez enfin laisser libre court à votre imagination concernant votre flux de travail. Branches, rebase, merge…. Oui mais pour que le tout reste utilisable, surtout lorsque vous travaillez à plusieurs, il convient de régir tout ceci mais aussi de tenter de le conformer le plus possible à vos contraintes réelles — développement, production, tests…. Bref, il convient de définir un flux de travail — un workflow.
Plutôt que de simplement vous présenter notre workflow, vous trouverez ici le pourquoi et le comment, c’est au final ce qui est le plus important.
- Un workflow c’est quoi, et ça sert à quoi ?
- Et tu as des exemples ?
- Un workflow doit répondre à nos besoins
- Les objectifs
- Les contraintes
- Le résultat
- En résumé
- La mise en œuvre
- Et en pratique ?
- À suivre
- Pour aller plus loin
Un workflow c’est quoi, et ça sert à quoi ?
Lorsque vous développez un logiciel, au début tout est facile. Ça ressemble à un historique linéaire, c’est simple, c’est clair. Et c’est facile à utiliser. Voici par exemple la séquence de commandes que vous pouvez utiliser.
hack
hack
...
git add -p # vous utilisez -p, non ?
git commit
...
hack
...
git add -p
git commit
...Bon, ça c’est cool, c’est quand vous êtes tout seul.
Ensuite, le problème c’est que si on ne fait pas attention ça devient tout autre chose. Vous travaillez à plusieurs et, avec les meilleurs attentions du monde, vous voulez vous mettre à jour genre, tout le temps. Et allez, c’est parti pour un florilège de pull, push parfois avec des fusions ce qui peut aussi ramener un certain nombre de conflits.
hack
hack
...
git pull
# merge
git commit
git push
...
git pull
# merge
...
git pull
# merge
...
git commit
...Le problème, c’est que le résultat devient quelque peu… différent de ce qui était escompté. Pourtant, vous utilisez Git, on vous a toujours dit que les branches c’étaient bien, qu’il ne faut pas avoir peur des fusions, etc. L’un des difficultés provient du fait que, lorsqu’on utilise des DVCS à plusieurs — ou pas d’ailleurs — on crée automatiquement des branches divergentes même si il est d’usage d’avoir toujours une référence nommée et partagée (master soug Git). Et forcément, s’il y a branches divergentes et qu’on utilise Git de base, il y a forcément une prolifération du nombre de fusion puisqu’on tente, naturellement, de se maintenir à jour par rapport à la base de code commune. Voici par exemple le résultat qu’on peut obtenir.
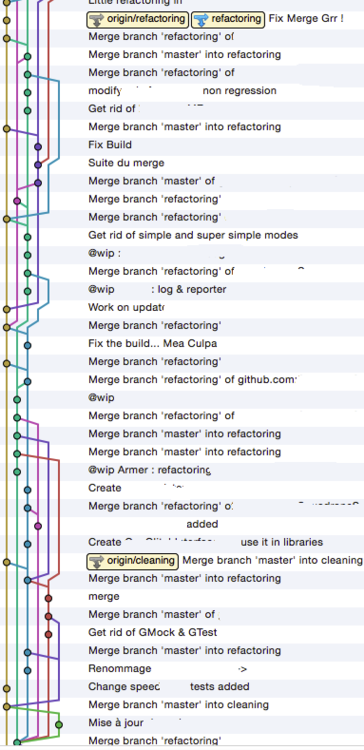
Pour info c’est un vrai historique hein 😉
Vous pouvez tout de suite voir les problèmes. L’historique devient très difficile à lire. Tentez par exemple de suivre une branche et les commits associés. C’est loin d’être évident. Imaginez alors lorsque vous devez faire du debug pour trouver dans tout ceci le commit qui a entrainé une régression. Et si vous regardez bien précisément vous pouvez y voir émerger une cause : le nombre de commit de fusion par rapport au nombre total de commit. Il y a des fusions dans tous les sens, pour se synchroniser, pour fusionner des fonctionnalités en cours de développement. Et il est facile d’imaginer que derrière ces commits se cachent quelques conflits.
Et si on en revenait à la question : « un workflow c’est quoi, et ça sert à quoi ? »
Un workflow — dans notre cas pour Git — c’est surtout la définition de comment on travaille en collaboration avec notre outil de gestion de sources et avec les autres personnes. Quelles sont les règles, mais surtout dans quel but. Il ne s’agit surtout pas de contraindre inutilement les possibilités. Mais pour ce faire, la première chose à se demander c’est justement quelles sont nos contraintes.
Et tu as des exemples ?
En fait, il y en a plein.
Dans les plus connus, si vous avez des développements en production avec branche de maintenance et autres, que vous faites du SemVer par exemple, il y a Git Flow :
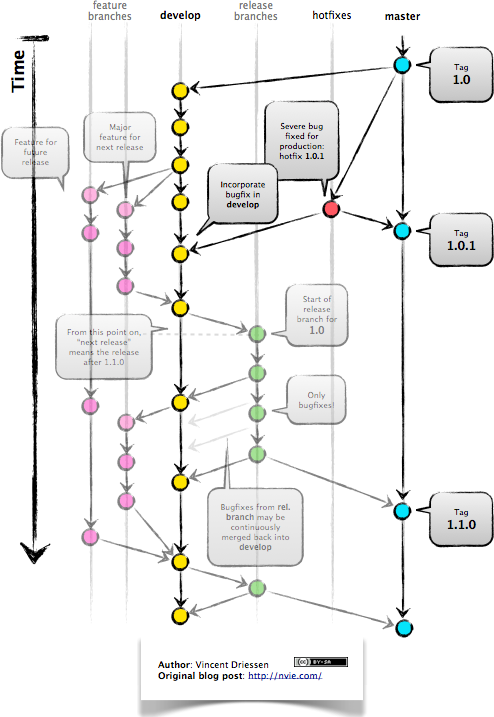
Vous pouvez trouver plus d’infos sur le lien précédent, sur le projet Github ou chez Atlassian.
A noter qu’il existe une variante pour mercurial, hgflow. Ces deux workflow sont d’ailleurs utilisables directement dans SourceTree, le client Git et mercurial édité par Atlassian.
L’autre workflow très courant aujourd’hui c’est le Github Flow.
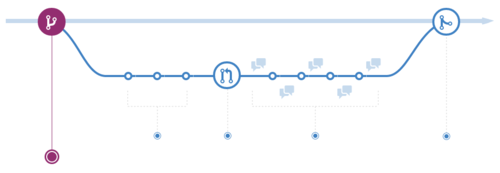
Il est très pratique si vous êtes dans le cadre de déploiement continu et si vous utilisez des systèmes comme Github / bitbucket / autre solution d’hébergement avec code review et pull request.
Un workflow doit répondre à nos besoins
Alors, s’il existe déjà des workflow, pourquoi ne pas en utiliser un déjà décrit ?
Déjà avant de savoir si on peut utiliser un workflow existant, il convient de savoir quels sont les objectifs visés et quelles sont nos contraintes. Ensuite, par l’étude de ceux-ci il devient possible de déterminer un workflow, soit un nouveau soit un existant.
Mais dans tous les cas un workflow se doit de nous aider, jamais de nous limiter ni nous empêcher de travailler.
Les objectifs
Nous voulons pouvoir :
- tester facilement chaque fonctionnalité “unitairement” (vous verrez un peu plus tard que c’est un point beaucoup plus complexe qu’il n’y parait…)
- avoir un historique très lisible pour pouvoir naviguer facilement dedans lors de la découverte de mauvais comportements
- pouvoir désactiver une fonctionnalité très facilement
- avoir le détail (les étapes) de chaque fonctionnalité
Les contraintes
Certains points à prendre en compte :
- pour le moment il n’y a pas de branches de production, maintenance, etc., mais ça pourra arriver un jour
- le corollaire c’est que pour le moment la branch principale doit toujours être stable
- il y a 7 (pour le moment) développeurs
- sprints de 2 semaines
- développement de logiciel mobile et de logiciel embarqué sur un drone (et là ça change tout…)
Le résultat
Je vais reprendre les objectifs et essayer de placer en face de chacun une “règle” Git, en prenant en compte si besoin nos contraintes.
-
Tester unitairement chaque fonctionnalité : Bon là c’est simple, tout le monde me dira « chaque fonctionnalité dans une branche dédiée ». Oui. Mais je vous répondrai « mais le code est dédié à un drone ».La branche pour une fonctionnalité (feature branch ou topic branch) c’est bien, à une condition importante, c’est qu’il existe un moyen de valider si cette branche est ok ou non avant de pouvoir l’intégrer dans le tronc commun. En général là on va parler de tests unitaires, d’intégration continue, etc. On a tout ça. Mais ça ne suffit pas. En effet, dans notre cas les tests unitaires, les tests de plus haut niveau, les simulations, l’intégration continue, tout ceci ne remplace pas — en tout cas pour le moment — des essais en vol, en extérieur. Le succès ou l’échec de notre code dépend aussi de différents matériels, de conditions extérieures — que se passe-t-il lorsque le GPS ou la communication est dégradé en plein vol parce qu’il y a des nuages ? — et pire, de ressentis visuels. Et plus que tout ceci, nous ne pouvons pas réaliser les tests en continu. Il faut se déplacer à l’extérieur pour réaliser les tests et dépendre alors de la météo. Donc nous souhaitons pouvoir tester plusieurs fonctionnalités d’un coup si c’est possible.Le résultat pour nous c’est tout de même une branche par fonctionnalité — what else? — plus une branche d’intégration spécifique à chaque itération. Lorsque nous partons en essais, la branche d’intégration comporte l’ensemble des fonctionnalités à jour ce qui permet, si tout se passe bien, de valider l’ensemble. Les fonctionnalités qui sont ok sont ensuite intégrées dans la branche principale
master. Si jamais cela se passe mal, il est possible de générer très facilement des versions pour chaque fonctionnalité et tester, valider ou invalider chacune. -
Avoir un historique lisible : L’objectif est vraiment de pouvoir naviguer facilement dans l’historique, essentiellement pour y rechercher la cause d’un mauvais comportement qui n’aurait pas été mis en évidence par les tests automatisés.La première solution à mettre en place c’est de limiter au maximum les commits “sans valeur”, par exemple les commits de synchronisation avec l’upstream, et garantir le meilleur rapport signal/bruit possible. Pour ça c’est assez facile, il suffit d’interdir les
pull/mergede synchronisation. Si on souhaite tout de même bénéficier d’améliorations qui sont dans le tronc commun, il faut utiliserrebasece qui linéarise l’historique.La deuxième chose c’est d’éviter au maximum les croisements de branches. La solution passe également par l’utilisation systématique derebaseavant d’intégrer les changements.Ceci doit permettre de ne pas avoir de commits inutiles et donc de pouvoir lire facilement l’historique car plus linéaire, moins plat de spaghettis. -
Pouvoir désactiver une fonctionnalité : Le scénario est le suivant : on détecte après coup une fonctionnalité qui pose problème (ou simplement on veut supprimer une fonctionnalité).Il faut alors pouvoir visualiser très rapidement la fonctionnalité et l’ensemble de ses modifications. La pire chose qui existerait c’est de faire du merge en fast forward, c’est-à-dire une linéarisation des commits de la branche. On les rajoute simplement au-dessus du tronc commun. Si on fait ça — et ceux qui ont fait du
svn(pouah !) connaissent très bien — il devient très compliqué d’identifier l’ensemble des modifications liées à une fonctionnalité. Et donc il devient très compliqué de les annuler.La solution est donc d’avoir tant que possible un unique commit pour chaque intégration de fonctionnalité dans le tronc commun. Si cela est fait, on peut annuler facilement par la réalisation d’un commit inversé. Vous pouvez utiliser directement la commandegit revertpour le faire. A ce moment de décision, vous avez deux choix :
- faire des merges systématiquement sans fast forward :
git merge --no-ff - faire des merges avec fusion de tous les commits en un seul :
<code>git merge --squash
- Avoir le détail de chaque fonctionnalité : Pour pouvoir débugger plus facilement mais aussi simplement relire et comprendre les modifications, il est intéressant de garder présentes les étapes de développement.
Ceci interdit donc l’utilisation de merge --squash au profit de merge --no-ff. En effet, dans ce cas nous avons un commit de merge mais la branche et donc le détail des opérations restent visibles.
Par contre, souvenez-vous, on parlait un peu plus haut d’historique propre. Dans ce cas la bonne pratique, avant de réaliser la fusion, est de nettoyer l’historique de la branche. Je vous encourage donc vivement l’utilisation de rebase --interactive voir même de rebase -i --autosquash — ça c’est une pratique qu’elle est bien ! Le but est d’améliorer les messages, fusionner certains commits entre eux voir même les réordonner ou les supprimer.
Le rebase va obliger à réécrire l’historique et donc probablement à forcer les push mais ce n’est pas grave, c’est une bonne chose d’avoir un historique propre.
En résumé
- une branche par fonctionnalité
- une branche d’intégration par itération
- synchronisation uniquement par rebase
- rebase obligatoire avant intégration
- fusion sans fast forward obligatoire
- nettoyage des branches avec du rebase interactif
La mise en œuvre
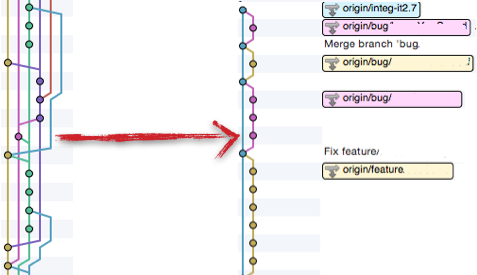
Vous vous souvenez de l’historique horrible du début de l’article ? Maintenant voici ce que cela donne :
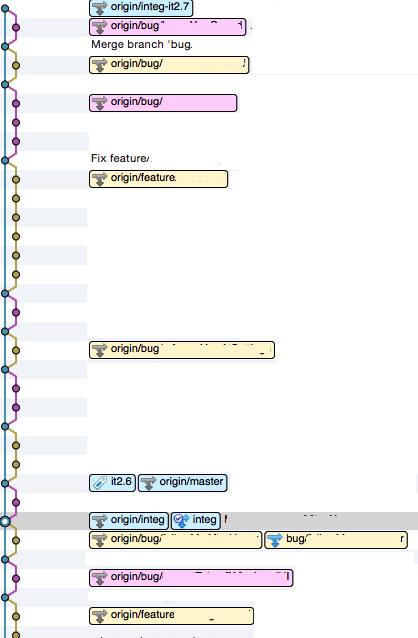
Ceci est une capture du vrai résultat, sur le même projet. Bon ok vous n’avez pas les commentaires des commits, mais voici ce qu’on peut en tirer :
- l’historique est clair et lisible, il est tout à fait possible de le comprendre et de se déplacer dedans sans craintes
- l’historique nous offre deux niveaux de détails :
- l’intégration de chaque fonctionnalité / bug / …
- le détail de chaque fonctionnalité / bug / …
- étant donné qu’il est facile d’identifier le commit d’intégration d’une fonctionnalité, il est aussi facile de l’annuler
- on voit que chaque fonctionnalité a été réalisée dans une branche dédiée, ce qui permet de la tester unitairement
- comme chaque branche a subit un
rebaseavant d’être fusionnée, il n’y a pas de croisements de branches, ce qui améliore la lisibilité - une branche d’intégration par itération est créée, puis si tout est ok, fusionnée dans
master. Vous le voyez avecorigin/integqui a été fusionné (en fast forward, c’est le seul cas) dansorigin/masteret tout ce qui est au-dessus est dansorigin/integ-it2.7et non dansmastercar l’itération est en cours. Evidemment il pourrait y avoir des branches non fusionnées dansinteg-it2.7.
Et en pratique ?
Voici les quelques commandes / principes que nous utilisons pour mettre en œuvre ce workflow.
-
On suppose qu’on débute une itération,
masterest propre. Par défaut toutes les branches vont avoir initialement comme originemaster.git checkout master git checkout -b integ -
Pour une fonctionnalité donnée, on crée une branche pour bosser dedans.
git checkout master git checkout -b feature/my-super-cool-feature
Nos branches sont préfixées pour améliorer la lisibilité :
feature/pour les fonctionnalitésbug/pour les anomaliesrefactor/pour ce qui est lié à du pur refactoring (on en a beaucoup puisqu’on se base sur un existant pas toujours propre…)
-
On développe dans la branche.
git checkout feature/my-super-cool-feature ... hack ... git add -p git commit ... hack ... git add -p git commit ... git push # avec -u pour configurer l'upstream la première fois ... -
S’il est nécessaire de se synchroniser, on rebase. Attention, j’insiste sur le nécessaire, si ce n’est pas obligatoire on ne le fait pas maintenant.
git checkout integ # je suppose que je suis dans ma branche de fonctionnalité git pull # comme on ne développe jamais dans master et qu'on fast forward master # on peut laisser le pull sans rebase git checkout - git rebase -
A ce moment, pour pousser mes modifications sur le serveur il faut que j’écrase la branche distante. Comme ce n’est qu’une branche de fonctionnalité et qu’il n’y a pas plusieurs personnes — hors binome — qui travaille dessus, c’est permis.
git push -f- Fusion dans la branche d’intégration. Pour commencer on se synchronise et rebase avec, cf
4.Ensuite on s’occupe de nettoyer la branche, avecrebase -ivoirrebase -i --autosquashsi vous avez pensé à l’utiliser. Enfin, on fusionne sans faire de fast forward.git checkout integ git pull git checkout - git rebase - git merge --no-ff integ
Concernant le message de commit il y a deux choix. Soit le nom de la branche est déjà explicite et ok, soit on met un beau message bien propre qui indique la fonctionnalité qu’on vient d’intégrer (à préférer).
Evidemment on pousse la branche d’intégration sur le serveur.
- Si les tests automatiques et non ont montré que la fonctionnalité ainsi que la branche integ sont ok, on peut fusionner integ dans master.
git checkout master git merge --ff git push
Etant donné qu’on vient de faire une fusion fast forward de integ, il n’est pas nécessaire de faire un rebase ou autre de cette dernière.
- On nettoie un peu nos branches, c’est-à-dire qu’on ne garde pas sur le serveur de branches fusionnées et terminées, histoire de garder un ensemble lisible.
git branch -d feature/my-super-cool-feature git push origin --delete feature/my-super-cool-feature
À suivre
=======
Aujourd’hui le workflow tel que défini est une aide précieuse dans notre développement. Il reste des points toujours délicats autour de la branche d’intégration. L’idéal serait de pouvoir valider nos modifications plus facilement, et donc de fusionner directement dans master et ne plus avoir cette branche intermédiaire. Mais cela est directement lié au métier et non une simple contrainte d’outillage.
Si nous voulions aller plus loin, il serait possible d’utiliser des pull requests entre les branches de fonctionnalité et la branche d’intégration, voir entre la branche d’intégration et master. Actuellement nous ne faisons pas de revue systématique mais travaillons beaucoup par binômage et en tournant sur tous les aspects du code. Le problème des pull requests est que la fusion depuis Github ne permet pas de facilement faire un rebase avant. Il faudrait le faire en dehors de l’outil, ce qui n’est pas terrible. Il existe par contre des forges qui permettent de réaliser ce type d’opérations.
Que pensez-vous de ce workflow ? Lequel utilisez-vous de votre côté, et surtout pourquoi ?
Pour aller plus loin
Si vous souhaitez aller plus loin, ou juste apprendre Git, nous donnons des formations Git.
Et si vous n’êtes pas rassasiés, voici une petite collection de liens à suivre :
- Git Flow
- Github flow
- Git revert
- Git rebase
- Git rebase -i
- Git rebase -i –autosquash
- Git rerere
- Si vous voulez comprendre pourquoi et comment utiliser rebase et avoir un historique propre, je vous conseille vivement ce post de Linus Torvalds sur la lkml. C’est plein de bons conseils pour bien utiliser Git.